
golang 1.20 http2源码解读
前言
搞清楚linux进程调度后,下一步就是网络。从最常见的http开始,考虑到java源码的冗长以及jvm的naive不透明,不如从golang入手。
本次解读基于golang 1.20。
Http 1.1
Http1.1应该是web协议中最简单的一个。一句话概括,给每个连接分配一个goroutine,goroutine负责读取请求-处理-发送响应,然后关闭连接或者在这个连接上循环做读取请求-处理-发送响应。
这整个过程都是同步且阻塞的。如图:
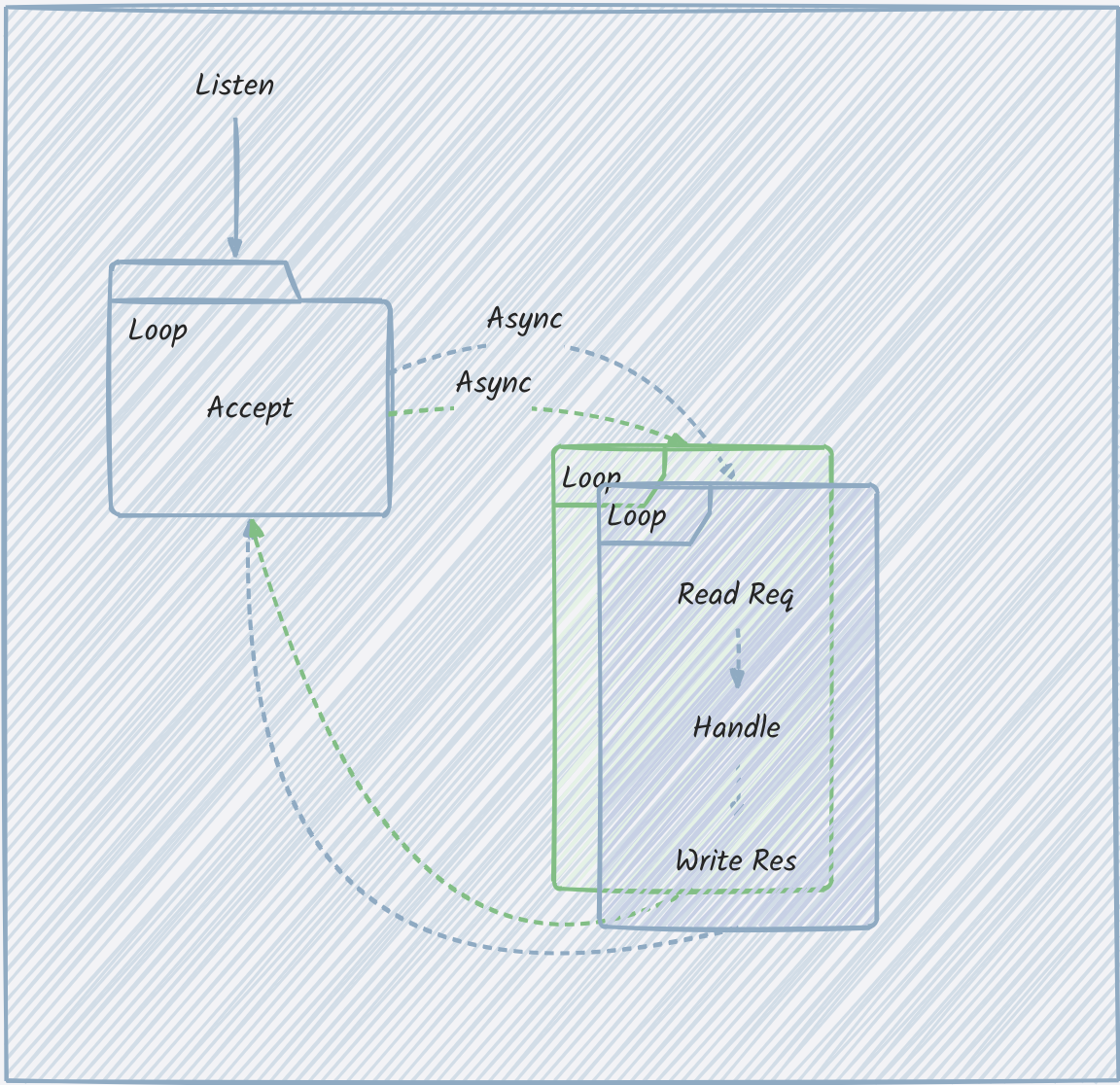
可以看到,Http1.1对于TCP链接的利用率很低,因为每个连接都是阻塞的,这就导致在Http1时代对于浏览器场景,为了加快速度,浏览器会开多个连接,而对于分布式应用,为了保证并发甚至需要维护一个连接池。
而这也直接导致了各种基于TCP的RPC框架的出现,比如dubbo,thrift等等。在这个阶段,RPC最核心的还是自定义协议以支持连接级别的多路服用,Stub反而只是锦上添花。
更糟糕的是每个连接都需要一个线程/协程,对于JAVA这种语言来说是不可接受的。当然,对于Golang来说由于goroutine足够cheap,并且结合epoll和goroutine的调度,开销对比JAVA会小很多。
源码也非常简单:
主goroutine
1 | server.ListenAndServe() |
每个连接一个goroutine
1 | // 读取请求 |
Http 2
Http 2克服了http1.1的几个严重的缺点,大幅的提升让gRPC/dubbo等一系列RPC框架都开始基于http2作为协议。让我们来探究一下goalng是如何实现http2的,以此窥见http2为什么可以高效。
简要介绍:
- 多路复用:HTTP/2 允许在一个 TCP 连接上同时进行多个请求和响应。这样可以减少因为建立多个 TCP 连接而产生的延迟,提高了资源的利用率。
- 头部压缩:HTTP/2 引入了 HPACK 压缩,可以减少请求和响应的头部大小,从而减少了网络传输的数据量。
- 服务器推送:HTTP/2 允许服务器在客户端需要之前就主动发送数据。这样可以减少了因为等待客户端请求而产生的延迟。
- 优先级和流量控制:HTTP/2 允许设置请求的优先级,这样可以让重要的请求更早地得到响应。同时,HTTP/2 还提供了流量控制机制,可以防止发送方压垮接收方。
- 二进制协议:HTTP/2 是一个二进制协议,这使得它比 HTTP/1.1 的文本协议更易于解析和更高效。
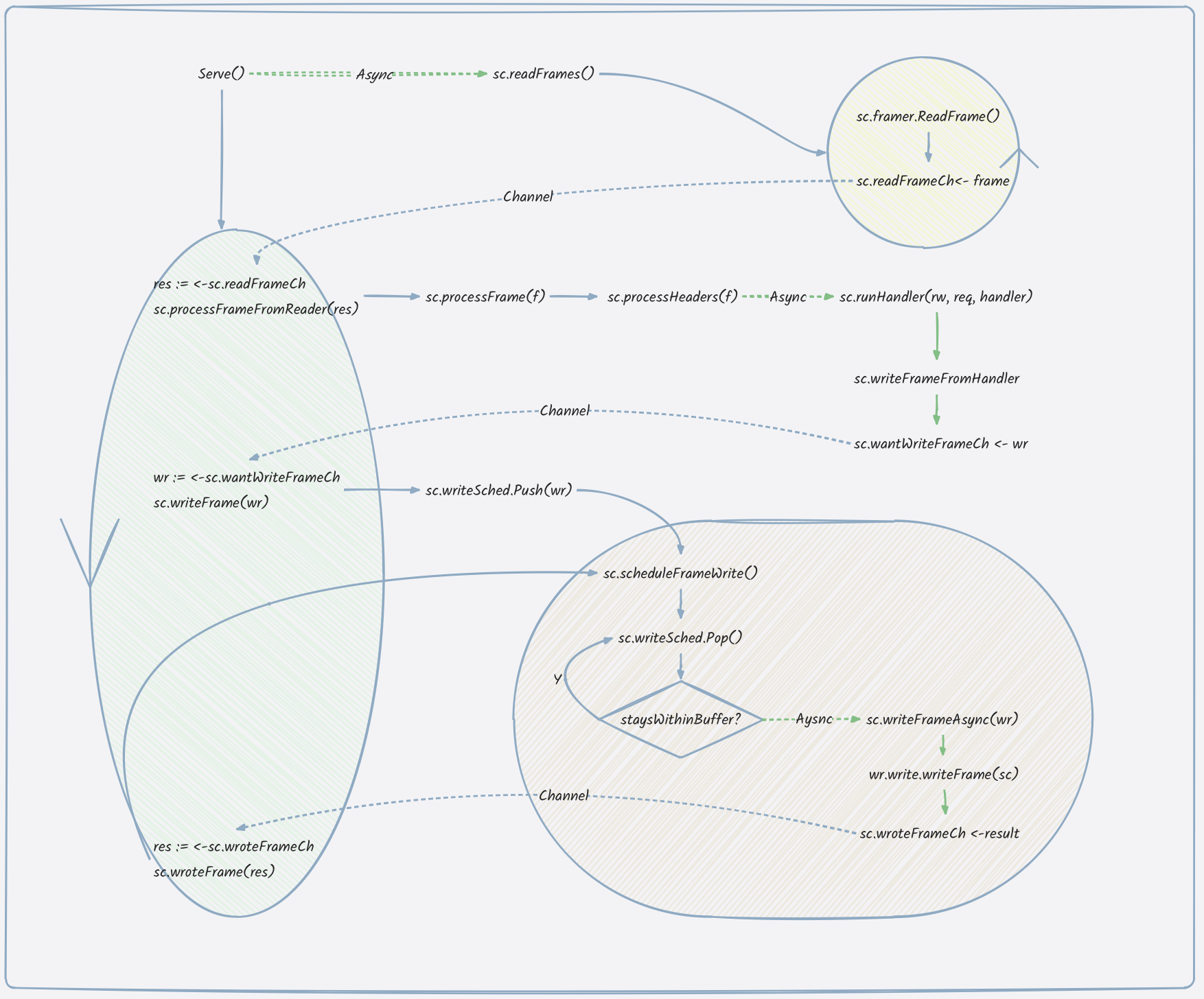
图中可以看出,golang http2在建立连接后,有一个独立的goroutine做readLoop,在读取完一个Frame后通过channel发送给主Loop goroutine,然后路由到对应的handler,此时开启一个新的handler goroutine
处理业务,处理结果会暂时写入writer的buf中,随后通过channel发送给主Loop goroutine,完成实际的写入。可以粗略的认为http2的实现分别使用了read/write两个goroutine,handler则是每个请求一个goroutine。
Http2入口
可以看到http2的入口和http1.1的入口是一样的,都是通过server.ListenAndServe()来启动的。
1 | http.ListenAndServe() |
1 | func (c *conn) serve(ctx context.Context) { // http2默认是要求开启tls的 |
主goroutine
1 | func (s *http2Server) ServeConn(c net.Conn, opts *http2ServeConnOpts) { |
ReadLoop
这里能够体现http2的优先级和流量控制以及二进制分帧。
为了实现多路复用,http2在一个tcp连接上虚构了一个stream的概念,一个请求-响应对应一个stream。这也导致http2不得不在tcp之上再次实现tcp上的流量控制,在这个基础上,自然而然的会有控制帧和数据帧的区别。
Header帧和Data帧属于进一步的拆分,目的是进一步提高链接的利用率和更细致的流量控制。
1 | func (sc *http2serverConn) serve() { |
sc.readFrames()在一个goroutine中循环读取帧,http2只需要一个goroutine就可以处理多个stream。
实际http1.1使用多个conn + goroutine并发读写是相当低效的做法,并发读写不止不能够提高效率,反而会降低。
Handler and WriteLoop
1 | for { |
sc.writeFrame(wr)主要是将写入的动作使用sc.writeSched.Push(wr)追加到写入队列中,然后触发一次sc.scheduleFrameWrite()
sc.scheduleFrameWrite()会从sc.writeSched拉取写入请求,如果该请求可以写入到writer buf中,则直接在主goroutine中写入buffer,否则开启一个新的goroutine异步写入,因为该次写入很有可能是阻塞的。
完成后触发一次wroteFrame
sc.wroteFrame(res) sc.scheduleFrameWrite()写入完成后会触发一次sc.wroteFrame(res),然后检查请求是否结束关闭stream,再触发一次sc.scheduleFrameWrite()
至此,http2的解析就完成了,如果读者熟悉netty等框架会发现,似乎golang使用了多个goroutine并发读写多个tcp连接,而且读取和写入是同步阻塞的,这似乎与netty的一个或少数几个线程负责读写所有的tcp连接
方式不同,golang似乎使一些goroutine资源白白等待,但事实并发如此,实际上….
请关注下一篇,net.Listen的黑魔法。

